Integrate with PyTorch¶
PyTorch is a popular open source machine learning framework based on the Torch library, used for applications such as computer vision and natural language processing.
PyTorch enables fast, flexible experimentation and efficient production through a user-friendly front-end, distributed training, and ecosystem of tools and libraries.
Instrument PyTorch with Comet to start managing experiments, create dataset versions and track hyperparameters for faster and easier reproducibility and collaboration.
![]()
Note: If you are using Pytorch Tensorboard, see our Tensorboard Integration.
Note: This integration also supports PyTorch Distributed Data Parallel. See below.
Start logging¶
Connect Comet to your existing code by adding in a simple Comet Experiment.
Add the following lines of code to your script or notebook:
import comet_ml
from comet_ml.integration.pytorch import watch
import torch
experiment = comet_ml.start()
# Your code here
model = get_model()
watch(model)
Note
There are other ways to configure Comet. See more here.
Log automatically¶
After an Experiment has been created, Comet automatically logs the following PyTorch items, by default, with no additional configuration:
- Model and graph description
- Training loss
You can easily turn the automatic logging on and off for any or all items. See Configure Comet for PyTorch for more details.
Note
Don't see what you need to log here? We have your back. You can manually log any kind of data to Comet using the Experiment object. For example, use experiment.log_image to log images, or experiment.log_audio to log audio.
End-to-end example¶
Following is a basic example of using Comet with PyTorch.
If you can't wait, check out the results of this example PyTorch experiment for a preview of what's to come.
Install dependencies¶
python -m pip install "comet_ml>=3.44.0" torch torchvision tqdm
Run the example¶
# coding: utf-8
from comet_ml import start, login
from comet_ml.integration.pytorch import log_model, watch
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
hyper_params = {
"sequence_length": 28,
"input_size": 28,
"hidden_size": 128,
"num_layers": 2,
"num_classes": 10,
"batch_size": 100,
"num_epochs": 5,
"learning_rate": 0.01,
}
# Login to Comet if needed
login()
experiment = start(project_name="comet-example-pytorch-doc")
experiment.log_parameters(hyper_params)
# MNIST Dataset
train_dataset = dsets.MNIST(
root="./data/", train=True, transform=transforms.ToTensor(), download=True
)
test_dataset = dsets.MNIST(root="./data/", train=False, transform=transforms.ToTensor())
# Data Loader (Input Pipeline)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=hyper_params["batch_size"], shuffle=True
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=hyper_params["batch_size"], shuffle=False
)
# RNN Model (Many-to-One)
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# Set initial states
h0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
c0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
# Forward propagate RNN
out, _ = self.lstm(x, (h0, c0))
# Decode hidden state of last time step
out = self.fc(out[:, -1, :])
return out
rnn = RNN(
hyper_params["input_size"],
hyper_params["hidden_size"],
hyper_params["num_layers"],
hyper_params["num_classes"],
)
# Loss and Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr=hyper_params["learning_rate"])
# Train the Model
total_steps = len(train_dataset) // hyper_params["batch_size"]
with experiment.train():
watch(rnn)
step = 0
for epoch in range(hyper_params["num_epochs"]):
experiment.log_current_epoch(epoch)
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
images = Variable(
images.view(
-1, hyper_params["sequence_length"], hyper_params["input_size"]
)
)
labels = Variable(labels)
# Forward + Backward + Optimize
optimizer.zero_grad()
outputs = rnn(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Compute train accuracy
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += float((predicted == labels.data).sum())
# Log accuracy to Comet.ml
experiment.log_metric("accuracy", 100 * correct / total, step=step)
step += 1
if (i + 1) % 100 == 0:
print(
"Epoch [%d/%d], Step [%d/%d], Loss: %.4f"
% (
epoch + 1,
hyper_params["num_epochs"],
i + 1,
total_steps,
loss.data.item(),
)
)
with experiment.test():
# Test the Model
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(
images.view(-1, hyper_params["sequence_length"], hyper_params["input_size"])
)
outputs = rnn(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += float((predicted == labels).sum())
experiment.log_metric("accuracy", correct / total)
print(
"Test Accuracy of the model on the 10000 test images: %d %%"
% (100 * correct / total)
)
# Log the model to Comet for easy tracking and deployment
log_model(experiment, rnn, "Pytorch-Mnist")
Try it out!¶
Don't just take our word for it, try it out for yourself.
- For more examples using PyTorch, see our examples GitHub repository.
- Run the end-to-end example above in Colab:

Weights/Biases and Gradients logging¶
You can log your Pytorch model Weights, Biases and Gradients during training with just one additional line of code, using watch:
from comet_ml import start, login
from comet_ml.integration.pytorch import watch
login()
experiment = start()
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
...
def forward(self, x):
...
return x
# Initialize model
model = TheModelClass()
watch(model)
This will log of your Model layers Weights, Biases and Gradients regularly during training. These will be logged as histograms on the Experiment Histograms tab.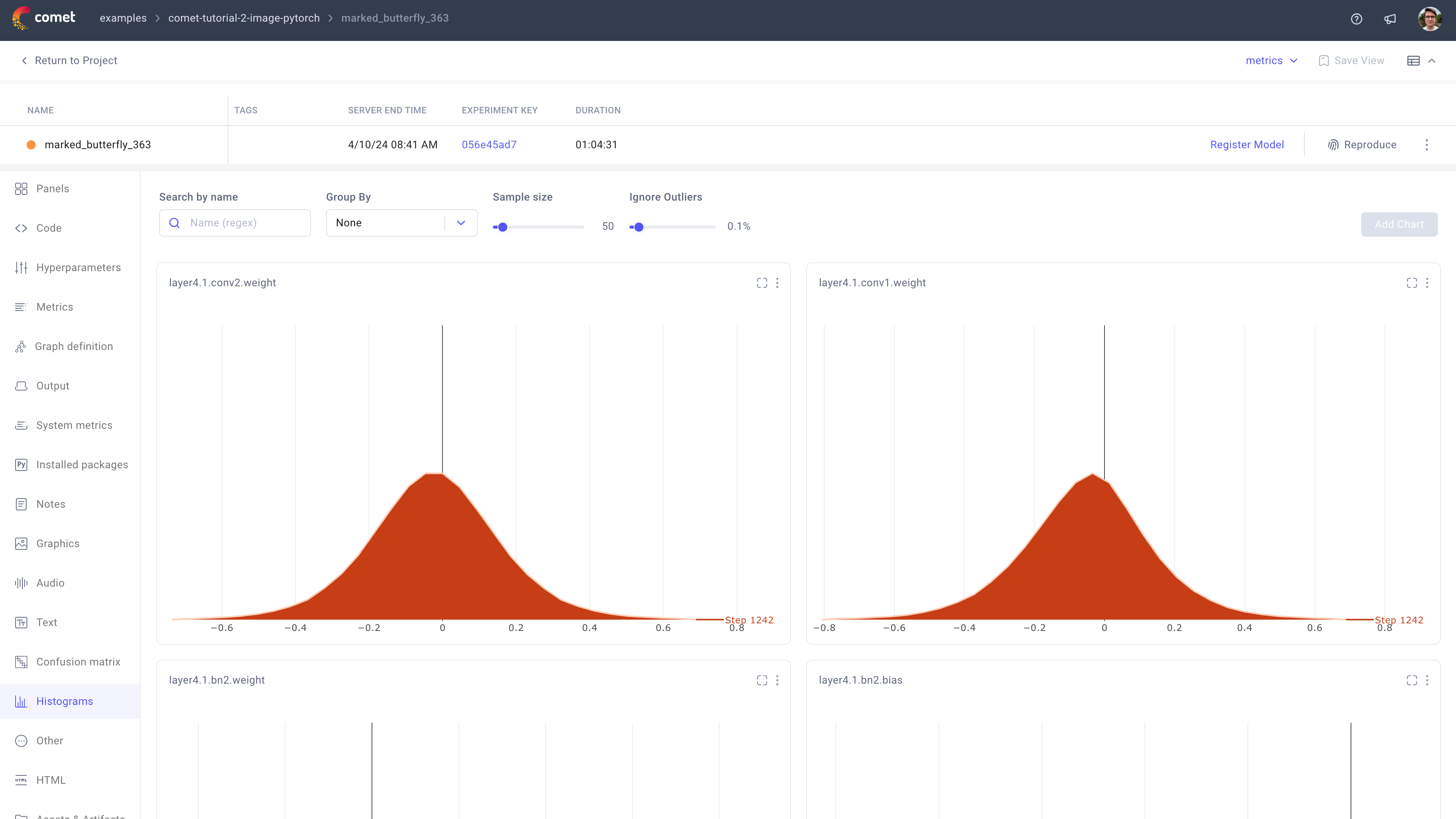
Check out the reference documentation for more details.
Pytorch model saving and loading¶
Comet provides user-friendly helpers to allow you to easily save your model and load them back.
Saving a model¶
To save a Pytorch model, you can use the comet_ml.integration.pytorch.log_model helper like this:
from comet_ml import start, login
from comet_ml.integration.pytorch import log_model
login()
experiment = start()
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
...
def forward(self, x):
...
return x
# Initialize model
model = TheModelClass()
# Train model
train(model)
# Save the model for inference
log_model(experiment, model, model_name="TheModel")
The model file will be saved as an Experiment Model which is visible in the Experiment assets tab. From there you will be able to register it in the Model Registry.
The previous code snippet is tailored for inference needs. If you want to log a general checkpoint for Resume Training, you can update the last line of the snippet to be:
# Save the model for Resume Training
model_checkpoint = {
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"loss": loss,
...
}
log_model(experiment, model_checkpoint, model_name="TheModel")
comet_ml.integration.pytorch.log_model is using torch.save under the hood, consult the official Pytorch documentation for more details and for instructions for more advanced use-cases.
Check out the reference documentation for more details.
Loading a model¶
Once you have saved a model using comet_ml.integration.pytorch.log_model, you can load it back with its counterpart comet_ml.integration.pytorch.load_model.
Here is how you can load a model from the Model Registry for Inference:
from comet_ml.integration.pytorch import load_model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
...
def forward(self, x):
...
return x
# Initialize model
model = TheModelClass()
# Load the model state dict from Comet Registry
model.load_state_dict(load_model("registry://WORKSPACE/TheModel:1.2.4"))
model.eval()
prediction = model(...)
You can load Pytorch Model from various sources:
file://data/my-model, load thestate_dictfrom the file pathdata/my-model(relative path)file:///path/to/my-model, load thestate_dictfrom the file path/path/to/-my-model(absolute path)registry://<workspace>/<registry_name>, load thestate_dictfrom the Model Registry identified by the workspace and registry name, take the last version of it.registry://<workspace>/<registry_name>:version, load thestate_dictfrom the Model Registry identified by the workspace, registry name and explicit version.experiment://<experiment_key>/<model_name>, load thestate_dictfrom an Experiment, identified by the Experiment key and the model_name.experiment://<workspace>/<project_name>/<experiment_name>/<model_name>, load thestate_dictfrom an Experiment, identified by the workspace name, project name, experiment name and the model_name.
The previous code snippet is tailored for inference needs. If you want to load a general checkpoint for Resume Training, you can update the last line of the snippet to be:
# Initialize model
model = TheModelClass()
# Load the model state dict from a Comet Experiment
checkpoint = load_model("experiment://e1098c4e1e764ff89881b868e4c70f5/TheModel")
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.train()
comet_ml.integration.pytorch.load_modle is using torch.load under the hood, consult the official Pytorch documentation for more details and for instructions for more advanced use-cases.
Check out the reference documentation for more details.
PyTorch Distributed Data Parallel¶
Are you running distributed training with PyTorch? There is an example for logging PyTorch DDP with Comet in the comet-example repository.
Configure Comet for PyTorch¶
You can control which PyTorch items are logged automatically. Use any of the following methods:
experiment = comet_ml.start(
log_graph=True, # Can be True or False.
auto_metric_logging=True # Can be True or False
)
Add or remove these fields from your .comet.config file under the [comet_auto_log] section to enable or disable logging.
[comet_auto_log]
graph=true # can be true or false
metrics=true # can be true or false
export COMET_AUTO_LOG_GRAPH=true # Can be true or false
export COMET_AUTO_LOG_METRICS=true # Can be true or false
For more information about configuring Comet, see Configure Comet.